
碎碎念
近期公司的任务很忙,而且都特别急。原本以为分到一些文本类任务能轻松一点,结果没想到反而更忙了,整个人每天都转得飞起。
不过再忙,博客还是得折腾的。毕竟这玩意儿已经算是我上班之后为数不多的乐趣了。(叼毛西岑,也没个什么好玩的地方。)
最近也重新思考了一下博客的设计,最后决定还是不按照之前的方案去做右下角菜单了。右下角没了,那菜单总得找个新地方放,思来想去,感觉还是顶部最合适。
不过顶部空间毕竟有限,参考了一下洪哥的做法之后,我也决定整一个类似中控台的东西,把各种功能入口都集中放进去。
除了菜单之外,我还顺手加了一些其他功能。比如之前有群友提到默认字体的问题,现在使用的是我个人比较喜欢的字体,但我也能理解,有些人可能觉得这种字体不够清晰,或者不符合自己的阅读习惯。所以我专门做了一个字体切换功能,可以在浏览器默认字体和悠哉文楷之间自由切换。
除此之外,音乐播放器、评论弹窗、右键菜单这些功能,也都陆陆续续加上了开关。基本上本站自己额外折腾出来的一些功能,现在都支持按需开启或者关闭。
毕竟有些人喜欢花里胡哨一点的页面,有些人则更喜欢纯净的阅读体验。既然如此,那不如把选择权交给用户自己决定。我也尽量在功能和体验之间找一个平衡点,希望能够兼顾大部分人的使用习惯。
说回正题。
最近用了非常多的 AI 工具和模型,包括 Claude、OpenAI、Kimi,还有公司内部部署的 GLM。除了模型之外,也体验了不少配套工具,比如 OpenCode、Claude Code、Codex、Gemini CLI 等等。
前前后后折腾下来,用过的工具确实不少,但真正留在我电脑里的其实只有三个:Claude Code、Codex,以及一个主打开源生态的 KiloCode。
至于为什么最后会留下它们,又为什么放弃了其他工具,这篇文章就来聊聊我自己这段时间接触 Vibe Coding 的一些经历,以及一些个人的使用感受,希望能给刚接触这类工具的朋友提供一点参考。
模型公司
首先,Claude Code和Claude是两码事,有些靓仔总问我,煮啵煮啵,Claude Code不是不让咱用嘛?你是怎么用的嘞?在此声明一下,Claude Code只是一个工具,而Claude才是模型,比如我们市面上见到的Claude Opus 4.8,而Claude Code可以自行对接其他模型,包括但不限于Claude,GPT。
Anthropic
Anthropic公司不予置评,个人不太喜欢,但是不得不承认其模型能力还是比较强的,对应的价格也是居高不下。目前市面上比较便宜的大概在0.8r/$左右,模型能力确实不赖。虽然目前最新的Opus 4.7、4.8总感觉幻觉有点严重,甚至不如Opus 4.6满血,但仍然是Vibe Coding目前的天花板。
不建议买官网的,建议去一些中转站,价格实惠,还能接触到不同的模型。
目前Claude官方标价如下:
| 模型 | 上下文 | 输出 | 输入价格 | 输出价格 |
|---|---|---|---|---|
| Claude Haiku 4.5 | 200K | 64K | $1/M | $5/M |
| Claude Sonnet 4.6 | 1M | 64K | $3/M | $15/M |
| Claude Opus 4.6 | 1M | 128K | $5/M | $25/M |
| Claude Opus 4.7 | 1M | 128K | $5/M | $25/M |
| Claude Opus 4.8 | 1M | 128K | $5/M | $25/M |
| Claude Fable 5 | 1M | 128K | $10/M | $50/M |
其他模型懒得列了,目前你也就只能用到这些。最下方的Fable近期也被A\召回了,不让用了,所以只能用到上面这些。其中顶部两款分别用于文本整理和简单推理,下面三款用于日常编码,价格一样,也没什么挑的,选最好的即可。
OpenAI
下面就是大家耳熟能详的OpenAI了,2015年由萨姆·奥尔特曼创立,后面就用奥特曼简称。
从GPT5系列之前,其实我觉得OpenAI一直在走下坡路,虽然热度依旧很高,但代码能力和主流模型都有一定差距,从世界顶尖一下子被Anthropic超越,总感觉有点日落西山。不过从GPT5开始,能力瞬间提升,目前我认为是最佳的编码模型,没有之一。
OpenAI目前官方售价:
| 模型 | 上下文 | 输出 | 输入价格 | 输出价格 |
|---|---|---|---|---|
| GPT-5.4 nano | 400K | 128K | $0.20/M | $1.25/M |
| GPT-5.4 mini | 400K | 128K | $0.75/M | $4.50/M |
| GPT-5.3 Codex Spark | 128K | 32K | $1.75/M | $14/M |
| GPT-5.3 Codex | 400K | 128K | $1.75/M | $14/M |
| GPT-5.4 | 1.05M | 128K | $2.50/M | $15/M |
| GPT-5.5 | 1.05M | 128K | $5/M | $30/M |
| GPT-5.4 Pro | 1.05M | 128K | $30/M | $180/M |
| GPT-5.5 Pro | 1.05M | 128K | $30/M | $180/M |
看价格就知道不同模型的能力了,OpenAI不像Claude那么黑,顶级模型一个价,而是分段定价,新模型出来旧模型降价,这样大家也能按不同预算来选。
奥特曼最近优惠力度很大,在部分中转站甚至可以做到几分钱一刀,主流稳定的Pro也能做到两毛左右一刀,这极大降低了AI入门的门槛。
目前我个人建议主模型选5.4往上,子模型可以选5.3-Codex或者5.4-mini来处理能力要求较低的大段文本,这样能更大程度节约资源。如果有更高预算,建议上5.5,至于Pro模型……目前我还没用过,这标价太吓人了~
如果你最近打算入门Vibe Coding,恰好手里预算不多,建议尝试一下GPT系列模型。
智谱清言
海外的模型,我认为只需要了解这俩就够了,其他模型作用不仅限于Coding,比如某神秘X公司的AI,后续再分享一下国内的模型。
智谱清言旗下的GLM系列模型,是我认为目前国内唯一可用的编码模型。由于公司安全限制,我们只能用自行部署的一些模型,公司选了GLM-5.1,部署到了自己的算力集群里,所以我对这个模型体验最深。首先用下来,编码能力肯定没有海外模型强,但差距也不大,我相信最新的GLM-5.2会更强。
其计费如下:
| 模型 | 上下文 | 输出 | 输入价格 | 输出价格 |
|---|---|---|---|---|
| GLM-4.7 Flash | 200K | 131K | $0 | $0 |
| GLM-4.7 FlashX | 200K | 131K | $0.07/M | $0.40/M |
| GLM-4.6V | 128K | 32K | $0.30/M | $0.90/M |
| GLM-4.6 | 204.8K | 131K | $0.60/M | $2.20/M |
| GLM-4.7 | 204.8K | 131K | $0.60/M | $2.20/M |
| GLM-5 | 204.8K | 131K | $1/M | $3.20/M |
| GLM-5.1 | 200K | 131K | $6/M | $24/M |
以上只列了目前主流的模型,最新的5.2和更老的我懒得列了。
GLM系列的Flash一向免费,可以用来做摘要,效果还是挺不错的。剩下的就得付费了,目前主流的还是GLM-5和GLM-5.1。官网的Coding Plan套餐十分难买,需要十点钟限量抢购,可能要蹲一下。如果买到了Coding Plan,成本会更低一些。
GLM给我的感觉就是厚重,各部分都很中庸,但表现得很稳重、保守,代码写出来的能用,可能设计上差点,但最起码的功能是可以实现的。
月之暗面
代表作就是KIMI模型咯,KIMI模型刚开始给我的印象是用大文本作为宣传语的,也就是当前人们说的上下文,在能力上可能并不怎么出众,到后面渐渐演进,渐渐发展,到现在的顶流水平。
以下是价目表:
| 模型 | 上下文 | 输出 | 输入价格 | 输出价格 |
|---|---|---|---|---|
| Kimi K2.5 | 262K | 262K | $0.60/M | $3/M |
| Kimi K2.6 | 262K | 262K | $0.95/M | $4/M |
| Kimi K2.7 Code | 262K | 262K | $0.95/M | $4/M |
Kimi-K2.6期间,我买了个订阅,先不论模型的能力,我感觉订阅的额度有点过少,四五个小时也只能问个七八个问题就用完了,再就是模型能力,我感觉其审美能力还是可以的,但是在功能性上稍微差一点,写的代码有部分bug,所以我个人感觉还稍微达不到完全放手的水平,适合资深程序员用于辅助,在成本上是比GLM低很多的。
目前最新的Kimi-K2.7-Coding也出来了,模型能力应该会有大幅提升吧,毕竟都以Coding命名哩~
MiniMax
这家公司和前面的路线全然不同,其采用小参数量,全模态模型,来打通了另一个市场,以极为低廉的价格,拉低了Vibe Coding的门槛,所以套餐也是几家之中最为便宜的。
以下是官方价目表:
| 模型 | 上下文 | 输出 | 输入价格 | 输出价格 |
|---|---|---|---|---|
| MiniMax-M2.5 | 204.8K | 131K | $0.30/M | $1.20/M |
| MiniMax-M2.5 HighSpeed | 204.8K | 131K | $0.60/M | $2.40/M |
| MiniMax-M2.7 | 204.8K | 131K | $0.30/M | $1.20/M |
| MiniMax-M2.7 HighSpeed | 204.8K | 131K | $0.60/M | $2.40/M |
| MiniMax-M3 | 512K | 128K | $0.60/M | $2.40/M |
这家公司十分奇特,整体定位偏高性价比长上下文模型,在M3系列将上下文扩展到了512K,但整体仍然是工程型的路线,而不是极限能力的路线,其实我感觉这才是未来发展的趋势,而不是当前的力大砖飞,一味的堆叠参数量,确实会让模型能力最快的上升,但是成本也水涨船高,真正要做到的是,同等甚至更低的成本下,实现更好的效果,让Token的价格更加亲民,这才是科技的真正意义。
经过实测,其实模型能力出奇的好,写一些简单的任务还是可以的,但是参数量是硬伤,所以还是不要过于依赖,如果有大型工程项目还是选择模型能力更强的其他系列吧~
剩下的模型主播没有主流的用过,所以暂时就不评价啦,但是并不代表其能力差,比如Mimo等其他模型的能力也很强,完全能够和上面各种模型掰一掰,大家可以自己尝试一下啦!
中转站
这部分的链接有一定的AFF,注册后双方均可以获得额外的一定额度,如果介意请自行删掉后缀使用主域名访问即可~
注意自行判断中转站是否活着,一次不要塞太多钱,主播有的时候懒得更新,可能站炸了也没换……
以下关于倍率的描述,如没有明显声明,均以GPT系列最低渠道价格的模型为基准
这一部分感觉有点像广告的意思,但是确实是主播自己在用的中转站,也都是熟悉的群友开的,所以不要担心,真出了问题我会第一个揭竿为旗的~
当然,目前中转站管理不周,各种产品良莠不齐,并且存在反代国外资源的问题,相关部门已经开始了审查,所以以下站点仅对海外区域开放,境内区域理性使用哦~
中转站的计费总是千奇百怪,有的用灵石,有的用美刀,有的用欧元,有的用RMB,并且还有各种各样的倍率,总会让人眼花缭乱,所以主播的建议是,将所有价格换算成美刀,然后和官方价格对比,比如官方价格20$/Mtoken,而中转站换算下来是2$/Mtoken,那就是0.2倍率,倍率越低,成本越低,不过如果低到一定程度,就需要考虑一下是不是底层是豆包咯~
大部分站点采取的策略是,价格和官方同步,仅调整倍率,做到不同的渠道不同的价格,这里水比较深,所以建议付费的话,一次性不要太多,少量多次即可。
下面介绍几个作者自己在用的站点。
鱼鱼中转
站外引用 · 引用站外地址,不保证站点的可用性和安全性鱼鱼中转聚合多模型能力,一个密钥接入多节点,自动容灾、清晰计量。感谢鱼大善人提供的Token,本站绝大部分重构都是鱼鱼提供的API,前段时间价格低廉,管理相对宽松时是完全免费的,到后续,奥特曼高考完了,管控瞬间开始严格,导致号池丢的飞快,在这逆天的行情下,收费也不是很贵,算是同档之中最为便宜的了,目前倍率为0.05。
什么你说高峰期不稳定?不稳定直接电!

DuckCoding
站外引用 · 引用站外地址,不保证站点的可用性和安全性DuckCodingOne account, run Claude Code, CodeX, Gemini CLI这个站点是我在LinuxDo发现的,测试了一段时间,稳定性和速度都很高,倍率为0.1左右,价格还是比较优惠的,自行尝试一下哩~
ExtraLink
站外引用 · 引用站外地址,不保证站点的可用性和安全性ExtraLink AI通过统一、标准的接口协议接入海量模型。承载 AI 应用,高效管理数字资产,连接未来。这家站点也是一个网友自己维护的,除了服务器,他们还搞AI,当然服务器也很好用,目前我也在用哦~
目前提供了0.1倍率的GPT,以及0.8倍率的Claude模型,如果想体验一下各种顶级模型,欢迎自己看看哦~
这三个渠道可能不是最便宜的,但是应该足够你入门AI Coding啦,其他的也懒得介绍了,这里不适宜占用太多的篇幅。
工具
配置
拿到官方或者中转站的密钥后,就可以对接到Claude Code或者Codex之类的工具上了。这里建议下载一个CCSwitch,可以傻瓜式一键配置,地址如下:
如果你愿意匠心手搓,也可以找找对应的官方配置文档,比如Claude Code:
不过我还是更推荐CCSwitch。先安装你想用的编程工具,然后直接安装并打开CCSwitch,这里以Claude Code为例:
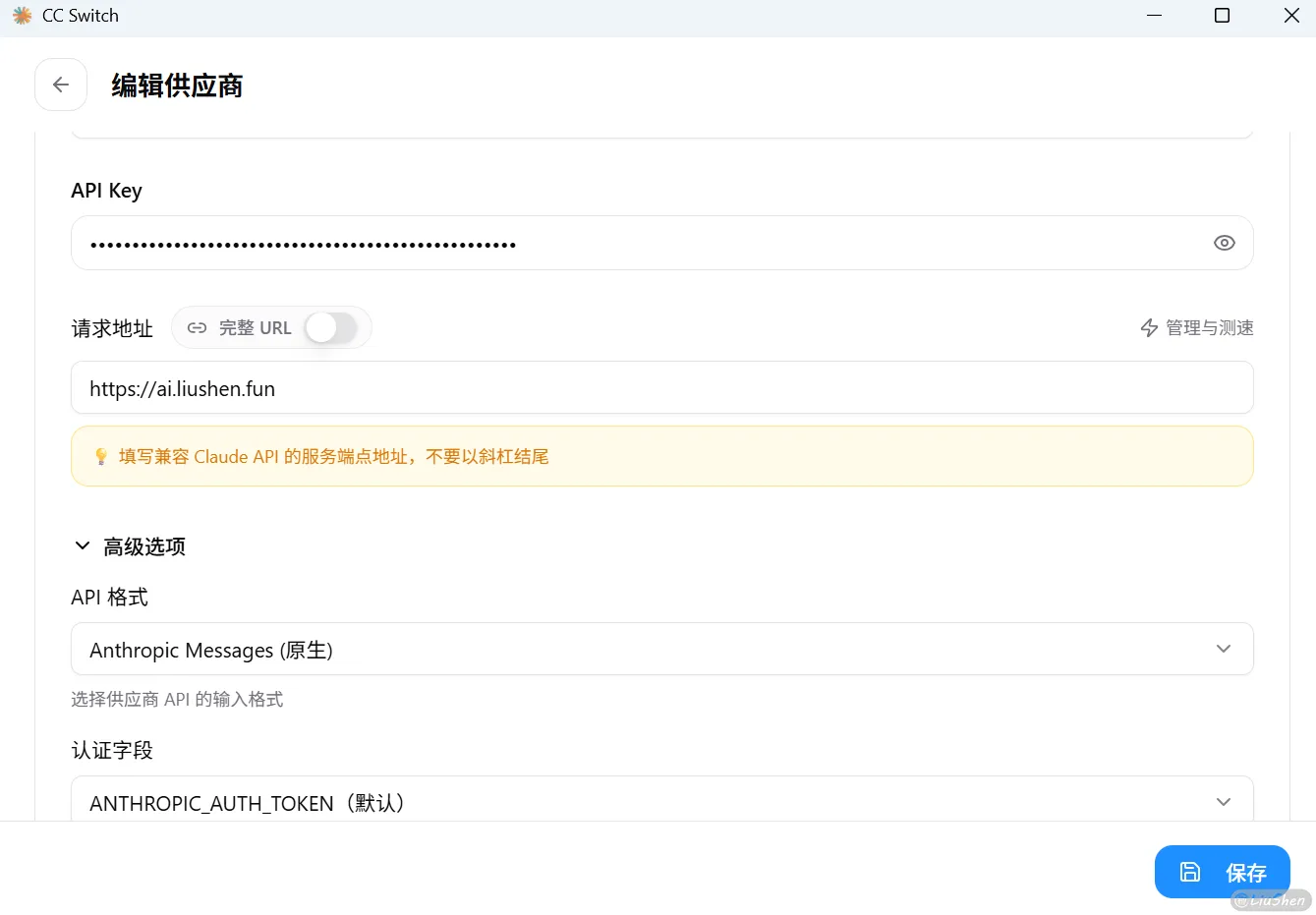
它会告诉你需要的配置,然后下滑找到高级选项,配置一下模型:
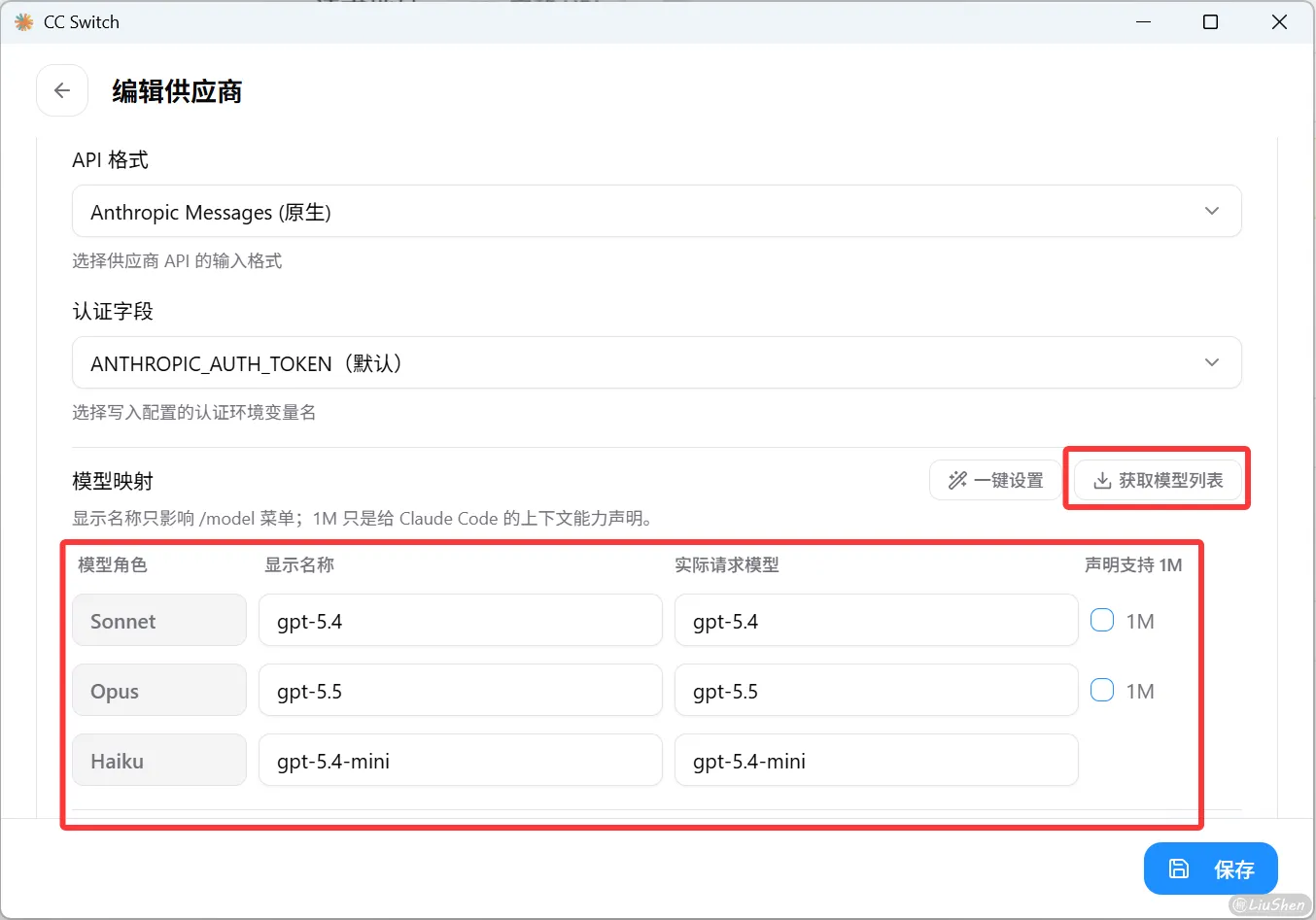
可以通过下拉框快捷配置,完成后点击保存,回到主页面启用即可。
Claude Code
在编程工具上,Claude Code说是第一应该没人敢说第二,其他的工具也很强,但仍在赶超的路上。
Claude Code内置的生命周期管理、提示词以及完善的工作流,都很值得学习。上手几乎不需要配置,就能实现一个很完善的标准开发流程。
由于公司电脑无法连接外网,没办法下载一些插件,只能手写一些Skill来稍微规范流程,倒也用的顺手。
前段时间Claude Code不小心开源了,各路大佬疯传源码,开发了各种Better版本,还从中挖掘出了很多Anthropic未来想发展的方向。能看出来,A\这点确实走在世界前列,但我相信,我们总有一天也能赶超。
Codex
除了上面那个,我用的最多的就是Codex了(因为一大堆中转站的API对Claude协议支持极差),最终也玩顺手了,现在基本都在用这个开发。虽然工程流没有Claude Code那么清晰,但差距也不大,而且基本都是流式请求,失败的概率小了很多。
Codex有一个/goal模式,可以在睡前启动一个任务,它会不断自我实现,直到完全实现为止。如果对接一个自我验证的Skill,效率会更高。
Codex可以走OpenAI接口使用,所以对GPT和各类Codex模型中转站的适配性更好。如果用的是形如”Codex号池”这类,那还是建议用Codex,否则会出现一大堆抽象的问题……
KiloCode
为什么推荐这个而不是原项目OpenCode呢?实际上我觉得OpenCode+OMO≈KiloCode,但OMO在Windows下的安装我个人感觉有点麻烦,所以最终选了KiloCode,对应的VSCode插件效果很不错,个人很喜欢这个风格。相比之下OpenCode的插件就有点简陋了,基本就是一个终端执行了OpenCode指令。
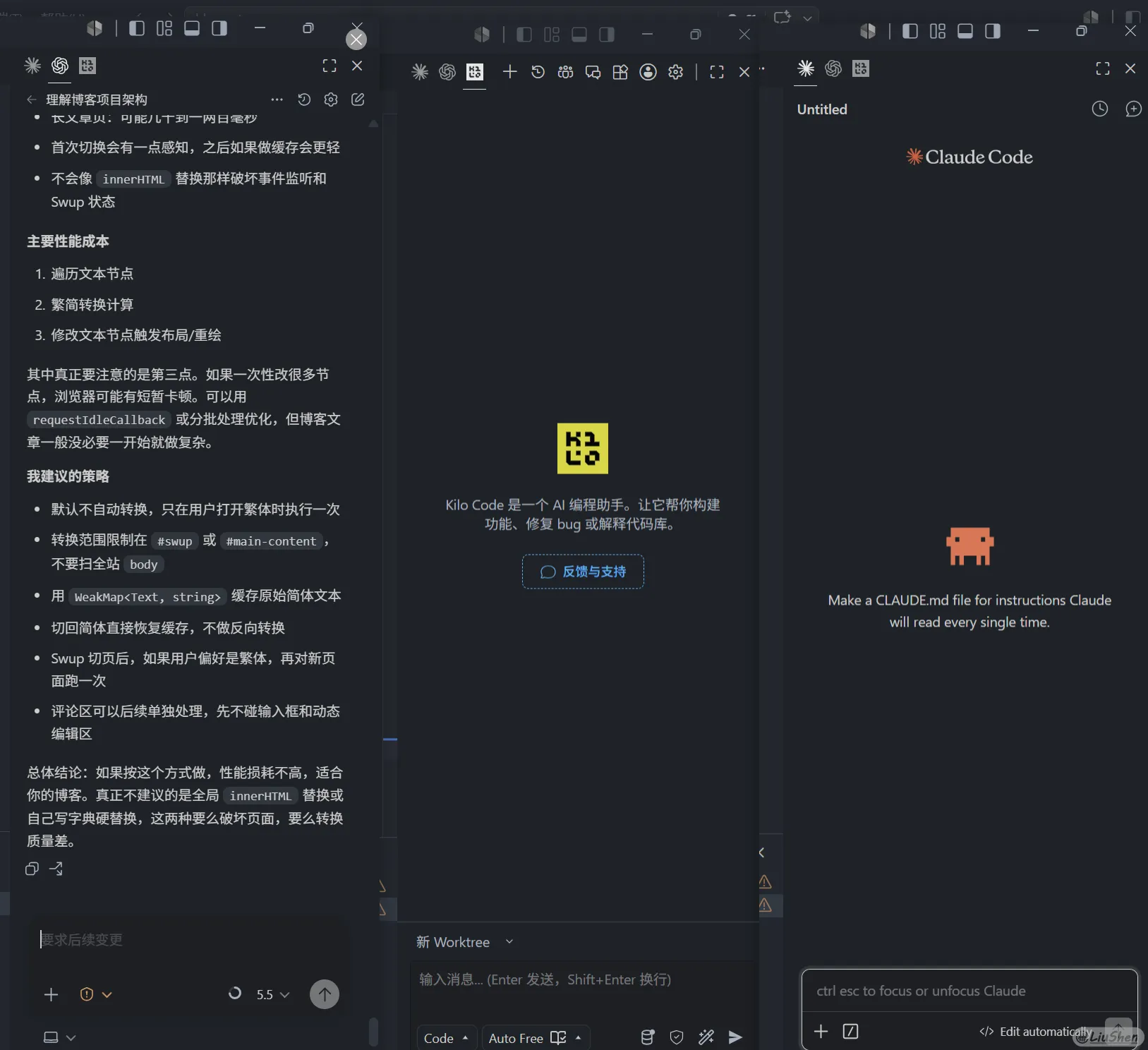
以上图片左中右分别为Codex、KiloCode、Claude Code。
虽然KiloCode在CCSwitch中目前无法配置,但其在VSCode的插件中有完善的配置页面,可以通过简单的GUI操作就能配全,这点我比较喜欢的。
相比之下,OpenCode需要基于Oh My Opencode才能实现多模型配置,略显麻烦。
贪多嚼不烂,工具其实是次要的,重要的是模型能力和个人的使用方式。如果你能提供完善的处理思路,那最简单的工具也能实现最优美的代码。
使用
安装完成之后,就可以开始真正使用它来写代码了。如果你是第一次接触这类工具,我个人建议一开始尽量选能力强一点的模型。不是说普通模型完全不能用,而是新手阶段本来就还没摸清楚 Vibe Coding 到底能做到什么,如果一上来就接一个能力比较一般的模型,很容易还没体验到上限,就先被各种奇怪的问题劝退了。
第一个问题
很多人第一次用 Vibe Coding 的时候,都会下意识把它当成聊天软件来用。上来先问一句“你好”,或者“你会写代码吗”,再或者直接来一句“帮我写个项目”。这些问题我以前也问过,但现在回头看,确实没什么太大意义。模型既然已经摆在你面前了,那它会不会写代码其实不用专门验证,真正需要验证的是:它到底能帮你做到什么程度。
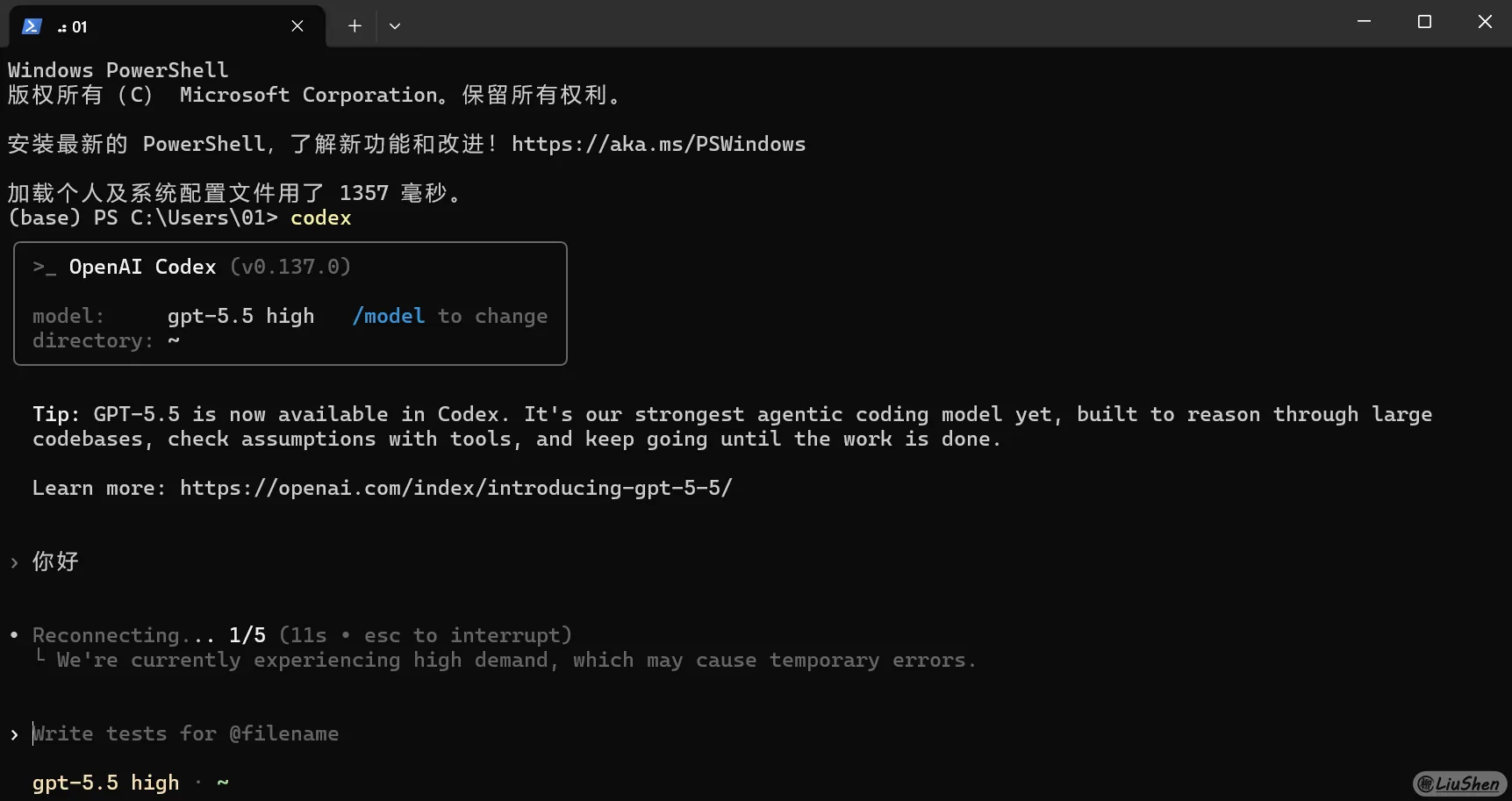
笑死你好都问不明白
很多人觉得 AI 不好用,本质上不一定是模型能力不行,而是提问方式出了问题。你给的信息越少,它就越只能靠猜;你问得越模糊,它回答得也越泛。最后看起来生成了一大段内容,好像哪里都对,但真拿去用的时候又发现没什么帮助,然后就开始怀疑这玩意儿是不是也就这样。
我真正开始大量使用 AI 开发,是因为公司当时正好提供了不限量的 API,于是我直接接入了 Claude Code。那时候我刚接手一个很大的项目,核心文件动不动就是几千行,目录结构也很复杂。对于刚接触项目的人来说,光是搞清楚各个模块之间的关系,就已经够折腾一阵子了。所以我第一个问题并不是让它写功能,而是直接把项目丢给它,让它帮我分析整个仓库。
结果还挺出乎意料的。它当然不可能一次性理解所有业务细节,但对于整体架构、模块划分、调用关系这些东西,它整理得非常快。很多原本需要我自己翻目录、看代码、查文档才能慢慢建立起来的认知,它几分钟就能帮我搭出一个大概框架。也是从那时候开始,我才意识到,AI 最有价值的地方不只是生成代码,而是能帮你快速理解一个陌生系统。
所以如果你是第一次使用 Vibe Coding,我不太建议从“你好”开始。不如直接拿真实项目问,比如:帮我分析一下这个项目的整体架构,主要模块分别负责什么;这个目录下面的代码都是做什么的,哪些是核心模块;如果我是新接手这个项目的开发者,应该优先阅读哪些文件;这个函数为什么要这样设计,有没有更好的实现方式;这段代码有没有潜在的性能问题或者安全风险;如果我要新增一个功能,应该从哪些模块开始改;或者帮我总结一下这个项目目前的技术栈和依赖关系。
这些问题有一个共同点,就是都基于真实上下文。当你开始围绕实际项目提问的时候,AI 才真正有机会发挥价值。它不是来陪你聊天的,而是来帮你理解代码、分析问题、提高效率的。现在我接触新项目时,基本都会先让 AI 帮我做一次整体分析,然后再结合自己的理解往细节里看。它不一定每次都完全正确,但至少能先帮我搭一个认知框架,把原本可能需要几天甚至更久的摸索过程,压缩到很短的时间里。
对开发来说,这种能力其实比单纯帮你写几行代码更有价值。
Skills
用了一段时间 Claude Code、Codex 之后,大概率会接触到另一个东西:Skills。我一开始也和很多人一样,看到网上有人推荐就疯狂安装。今天有人说 PUA 好用,明天有人说 NoPUA 更强,后天又冒出来什么架构师模式、全栈开发模式、高级工程师模式,甚至还有各种所谓的终极增强版。当时想法也很简单:既然大家都说好用,那多装一点总没坏处吧。

后来用了一段时间才发现,还真不是这么回事。很多人会把 Skills 理解成某种插件,觉得装了之后模型就会变聪明,代码质量会更高,架构能力也会更强。但实际上,大部分 Skills 本质上还是提示词。它不会凭空提高模型能力,只是在给模型增加一些规则、背景或者行为约束。这些东西当然可能有用,但它们同样会消耗上下文。
很多新手刚接触 Vibe Coding 的时候,很容易陷入一个误区:觉得模型效果不好,一定是因为自己装得不够多。于是开始疯狂往里面塞各种预设、规则和开发哲学。最后一个简单需求还没开始分析,上下文里已经先塞进去几千上万字。问题是,模型不会因为你写了一万字提示词就突然变聪明,反而还需要额外花精力去理解这些规则。更麻烦的是,有些规则之间可能还互相冲突,最后表现出来就是 Token 消耗越来越高,回复越来越长,但实际效果未必有明显提升。
尤其是网上经常讨论的那些 PUA、NoPUA 之类的东西,我个人一直比较谨慎。不是说它们完全没用,而是很多人其实根本没认真看过里面到底写了什么,只是看到别人一句“神级配置”“必装插件”,就直接复制进去用了。结果最后模型到底在遵循什么规则,自己都说不清楚。
所以如果你看到别人推荐某个 Skills,我的建议不是立刻安装,而是先打开看看里面到底写了什么。绝大部分 Skills 说白了就是一个 skills.md 文件,里面全是文本内容。既然如此,完全可以先把内容复制到当前会话里试试,看看模型表现有没有变化,回答质量有没有提升,开发体验是不是更符合你的习惯。如果用了几次之后确实感觉不错,再考虑长期安装也不迟。
反过来说,如果复制进去之后感觉和没加区别不大,那大概率说明这个东西对你的场景没有太大价值,也就没必要继续保留了。毕竟安装一个 Skills 的成本很低,但长期带着一个没什么作用的 Skills,消耗的可是真金白银的上下文费用。
我个人觉得,很多人其实误解了 Skills 的价值。它最适合的场景,并不是拿来“调教模型”,也不是通过一堆规则让模型强行扮演什么高级工程师。它真正有用的地方,是在特定场景下给模型补充背景信息。比如你正在维护一个长期项目,就可以在项目目录里放一个 skills.md,把项目架构、目录结构、核心业务流程、数据库设计、接口规范、开发约定、常用命令这些内容都写进去。
这样模型每次进入项目时,就能先知道这个项目大概是怎么回事。它不用每次都重新扫描整个仓库,也不用你反复解释项目背景。对于大型项目来说,这个帮助其实非常明显。很多时候模型回答不准确,并不是它能力不行,而是它缺少上下文。你只给它看一个文件,却希望它理解整个系统,这本来就不现实。但如果你提前通过 Skills 告诉它项目架构、模块职责和整体设计思路,它理解问题的速度就会快很多。
所以在我看来,Skills 更像是一份项目说明书,而不是能力增强插件。对于新手来说,我甚至建议前期不要过度折腾各种乱七八糟的预设。先把模型本身用明白,先学会怎么描述需求,怎么提供上下文,怎么拆分任务。等这些东西掌握之后,再根据自己的场景去补充少量真正有价值的 Skills。很多时候,一份写得清楚的项目文档,比十几个所谓的“神级预设”都管用。
毕竟现在这些顶级模型本身已经足够强了,大多数情况下限制它们发挥的,并不是能力,而是信息。给它正确的信息,比给它一堆花里胡哨的规则更重要。
写个一加一等于二的程序,用得着工程级代码吗?
如果一定要推荐一个比较适合新手体验的,我反而会推荐 SuperPower。它不是那种玄学预设,更像是在帮你把开发过程规范起来。很多刚开始接触 Vibe Coding 的人都有一个共同问题:想到什么就让 AI 写什么,功能能跑就行,完全没有设计过程。今天生成一个文件,明天新增一个模块,后天再改一个接口,写着写着项目就变成了一锅粥。
而且在 AI 的帮助下,这个问题会被进一步放大。以前你自己写代码,写累了就停了,写烦了也就不写了。但现在 AI 可以几分钟生成几千行代码,项目膨胀速度远远超过你的理解速度。最后你得到的可能不是一个项目,而是一坨能运行但没人敢动的代码。
SuperPower 的价值就在这里。它会倾向于让模型先分析需求,再设计方案,再拆分任务,最后进入实现阶段。很多时候它甚至会主动要求确认架构和设计思路,而不是上来就直接开写。对于已经有成熟开发习惯的人来说,这些东西可能没什么特别的,但对于刚接触 Vibe Coding 的新手来说,这种约束反而是一件好事。
因为大部分新手缺的从来不是代码生成速度,而是项目规划能力。所以如果你真的想试试 Skills,我觉得可以先从 SuperPower 这种偏开发流程管理的方案开始,而不是上来就安装各种神秘预设。至少它解决的是开发过程的问题,而不是试图通过几十页提示词去给模型洗脑。
总结
写到这里其实有点卡壳了,后面可能还是会再整理一些项目推荐、工具推荐之类的内容。毕竟这种偏经验分享的文章,我确实不算特别擅长,写着写着就有一种“再往下是不是该开始打广告了”的感觉,笑死。
不过不管怎么说,我还是挺建议大家去试试 Vibe Coding 的。不是说它现在已经完美了,也不是说用了之后就能立刻起飞,而是这东西确实代表了一种新的开发方式。很多事情以前需要自己一点点查、一点点试,现在可以让 AI 先帮你铺一层路,你再基于它的结果继续判断和推进。
我一直觉得,未来不是简单的“人被 AI 替代”,而是很多职业会被 AI 重新改造。纯粹重复、低价值、只靠堆时间的工作,肯定会越来越少;但能拆问题、能做判断、能把控方向的人,反而会变得更重要。因为当执行成本被 AI 大幅降低之后,真正值钱的东西就会变成:你知不知道要做什么,能不能判断做得对不对,以及能不能把一堆工具组织起来解决问题。
以前一个人可能只是一个开发,最多配合几个人一起做项目。以后很可能是一个人带着多个 AI 工作:一个帮你读代码,一个帮你写测试,一个帮你查资料,一个帮你做方案,一个帮你改 Bug。从某种意义上来说,一个人加上一组 AI,就已经有点像一个小团队了。
所以我觉得没必要对 AI 一直抱着特别强的危机感。危机肯定有,变化也肯定会带来淘汰,但这不是第一次发生这种事。每次工具升级,都会有人不适应,也会有人借着新工具把自己的能力放大很多倍。AI 带来的本质变化,是整体产出效率的提升。它会让一部分工作消失,也会让更多工作升格。
对普通开发者来说,最重要的可能不是纠结“AI 会不会抢我饭碗”,而是尽早搞清楚:怎么把 AI 变成自己的工具,怎么让它帮自己更快理解项目、更快验证想法、更快完成那些原本很消耗精力的事情。
总之,别把 AI 当成洪水猛兽,也别把它当成万能神仙。它就是一个很强的新工具,用得好能省很多事,用不好也可能给自己挖坑。
但不管怎么说,都值得亲自试试。
不管了,大家一起拥抱 AI 吧!
每日一图
图片来自哲风壁纸
