代码链接
DCAMNet个人修改后的代码链接,非官方!!!!,侵权请在文章尾部联系删除
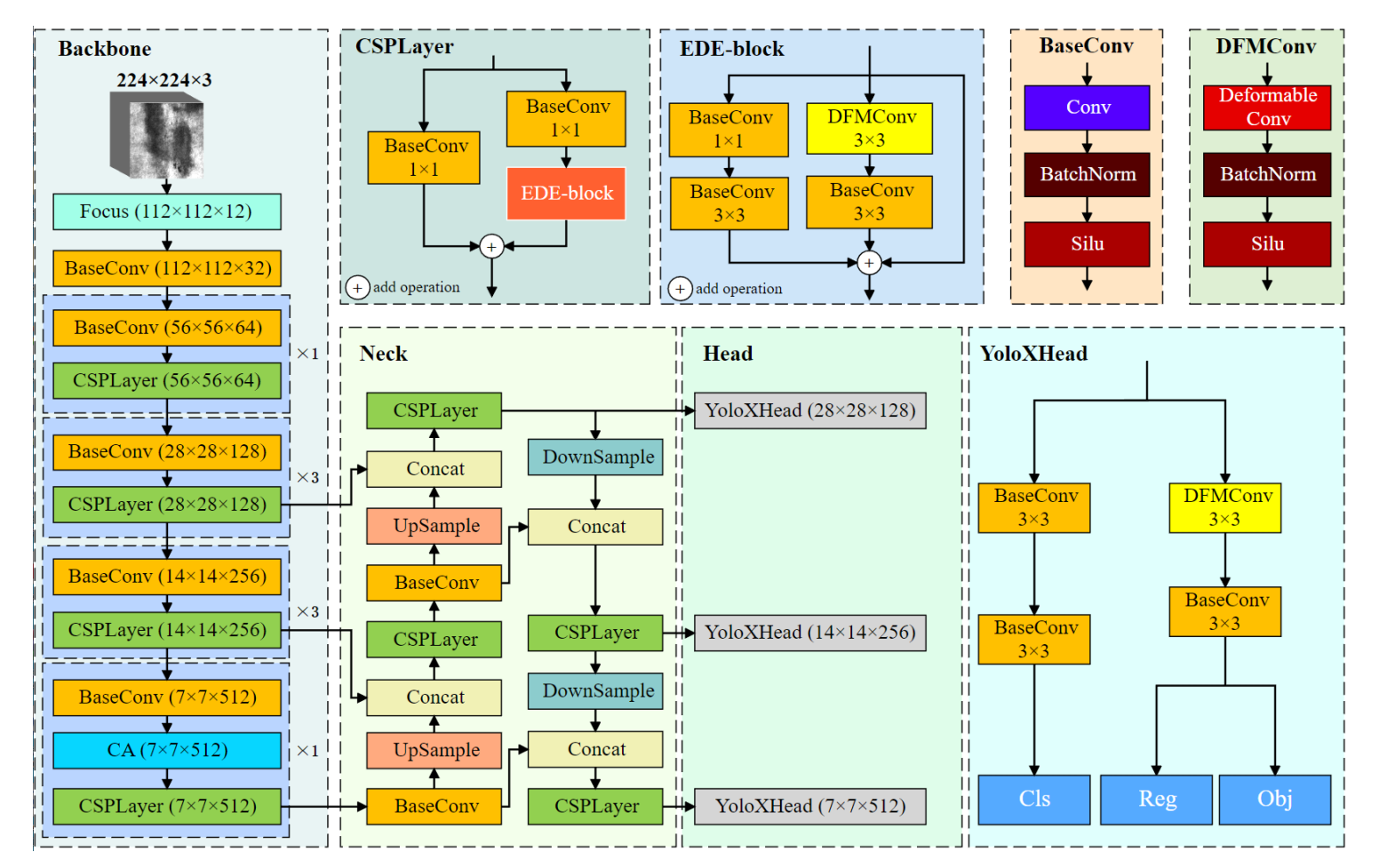
YOLOX网络结构与DCAMNet改进
YOLOX代码结构概述
文件夹结构
-
dataset: 包含两种数据集样式,COCO2017(JSON格式)和VOC2017(YML文件格式)。
-
demo: 提供基于 MegEngine、ONNX、TensorRT、OpenVINO 和 ncnn 的部署示例。
- MegEngine: 面向深度学习的框架,适合不同设备上的模型推理和部署。
- ONNX: 用于表示深度学习模型的开放格式,支持跨不同框架之间的模型共享和转换。
- TensorRT: 用于高性能深度学习推理的 NVIDIA 推理加速库。
- OpenVINO: 由英特尔提供的开源工具包,用于加速计算机视觉应用的开发和部署。
- NCNN: 面向移动端的高性能神经网络计算库,主要针对 ARM 架构优化。
-
Exps: 包含了对 YOLOX 文件的所有使用的配置文件。
MegEngine
-
MegEngine 是端到端深度学习框架,支持动态计算图和自动微分功能。
-
采用静态图优化、异步执行和自动内存管理,提高计算效率和资源利用率。
-
支持多种硬件后端,包括 CPU、GPU 和 AI 加速器。
ONNX
-
ONNX 是表示深度学习模型的开放格式,旨在实现跨不同框架和工具的模型互操作性。
-
使用中间表示(Intermediate Representation)表示模型结构和参数。
-
提供用于转换和优化模型的工具和库。
TensorRT
-
TensorRT 是 NVIDIA 提供的用于高性能深度学习推理的推理加速库。
-
针对 NVIDIA GPU 进行了优化,支持网络剪枝、量化和层次融合等优化技术。
-
支持多种硬件平台,提供用于优化和部署深度学习模型的工具和库。
OpenVINO
-
OpenVINO 是英特尔提供的工具包,用于优化和部署计算机视觉和深度学习模型。
-
利用模型优化技术,如量化、异步推理和硬件加速,使模型能够在英特尔的不同硬件上高效运行。
-
提供模型优化和部署的工具,适用于边缘计算和嵌入式设备。
NCNN
-
NCNN 是面向移动端和嵌入式设备的高性能神经网络计算库,主要针对 ARM 架构优化。
-
采用轻量级设计和高效的推理引擎,通过优化算法和硬件指令集提高模型在移动设备上的推理速度和效率。
Exps文件夹
- yolox_s: 本次修改我们使用该文件夹中的配置文件,定义了一些关键参数,如类别数、模型深度、宽度等。
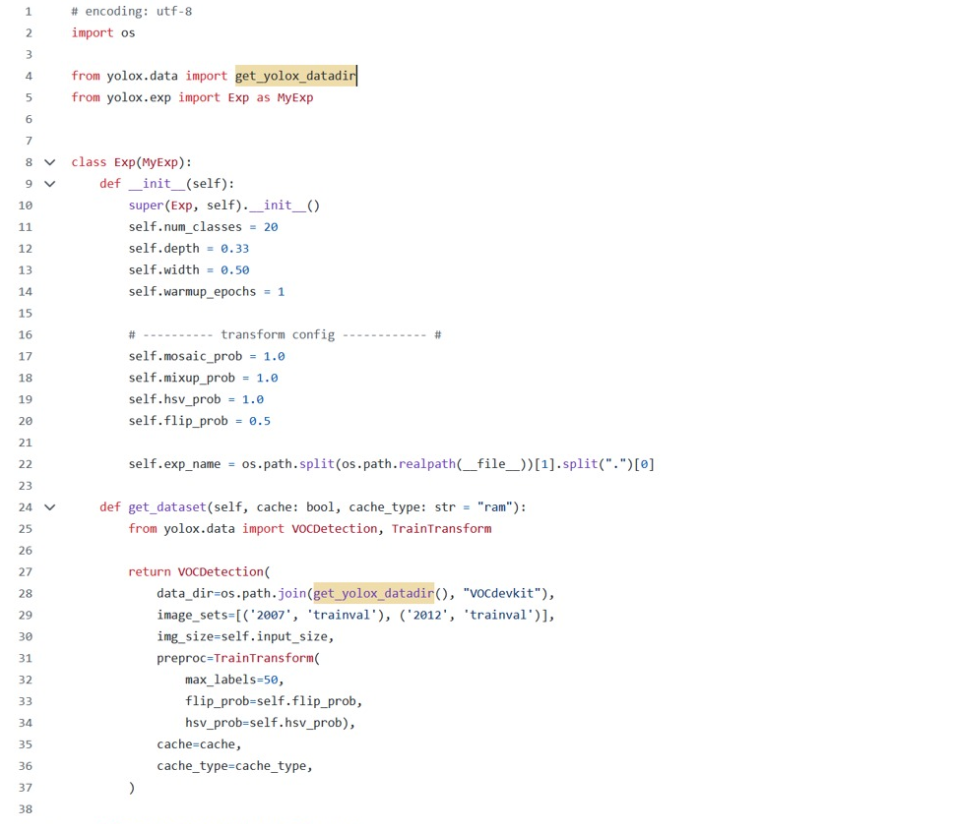
- Exp类: 继承了 YOLOX 的实验配置类 MyExp,重写了一些方法和属性,用于配置实验的细节。
-
**init 方法:** 设置模型训练参数,如类别数、模型深度、宽度等。
-
get_dataset 方法: 获取训练数据集,设置预处理参数,如 mosaic_prob(拼接图像的概率)、mixup_prob(混合训练的概率)等。
-
get_eval_dataset 方法: 获取评估所需的数据集,设置评估数据的相关参数。
-
get_evaluator 方法: 获取评估器,用于评估模型在数据集上的性能。
-
Tools文件夹
- train 文件: 用于传递各种训练参数。
YOLOX网络结构
-
YOLOX 检测算法基于 YOLO 系列,但对锚框生成模式进行了改进,引入无锚定(anchor-free)技术。
-
选择 YOLOX 作为基线网络,因其在不同数据集上的泛化能力较强,相对于传统锚框生成方法更灵活。
-
YOLOX 不需要手动调整锚框大小,提高了模型泛化能力。
YOLOX选择原因
-
现阶段检测算法的问题: 在YOLO系列上的检测头主要采用的聚类方法会导致模型在不同数据集上的泛化能力较差,训练后生成的锚框大多不能使用,导致大量的计算冗余,从而提高了计算成本和检测速度。而在带钢的表面缺陷图像数据中,由于缺陷之间的显著差异,聚类得到的锚框的大小更容易不稳定,会进一步影响检测网络模型的检测效果。
-
为什么选择YOLOX: 对比于YOLO系列网络,YOLOX检测头部分用无锚定(anchor-free)技术取代了基于锚定的技术。采用匈牙利算法作为参考,并设计了简化最优传输分配匹配算法,以减少模型训练过程中的许多冗余锚框。YOLOX不需要手动调整锚框的大小,从而提高了模型对不同图像的泛化能力。YOLOX对YOLOv3上的一系列改进有效地提高了检测效果和速度,特别对不同图像上的泛化性,所以作者选择了YOLOX作为基线网络。

- 现阶段YOLOX仍有的不足之处: 由于残余结构的设计问题,YOLOX的骨干网络难以更好地改进带钢表面缺陷特征的提取,再就是由于动态样本匹配的问题,YOLOX在检测带钢这种不规则缺陷对象方面的性能较差。与YOLO系列中传统的anchor-based的方法相比,YOLOX对复杂纹理的缺陷对象的检测性能较差,精度较低。

DCAMNet 改进
数据集修改
- 将数据集分为测试集和训练集,按照 VOC 格式修改数据集格式。
模型改进
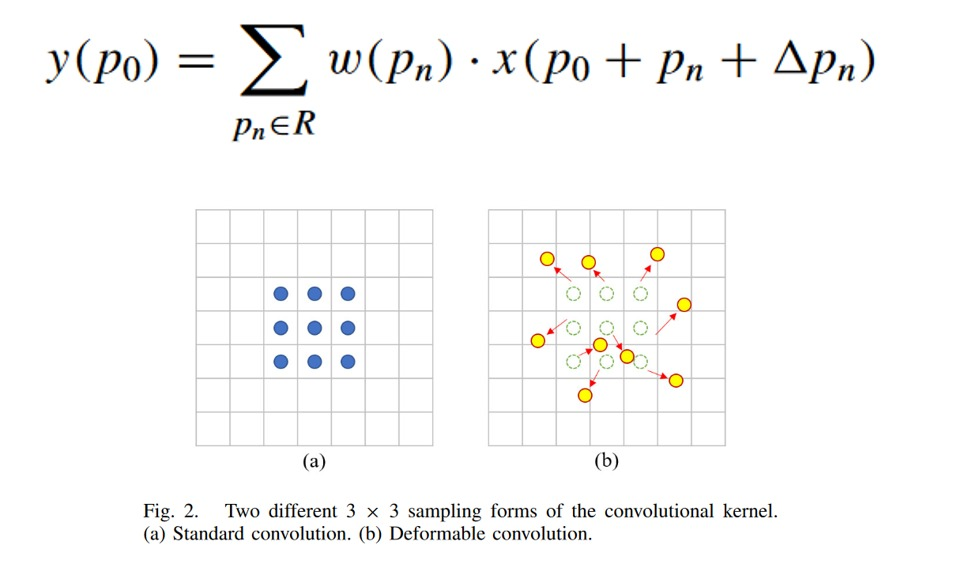
- CSPLayer 添加可变性卷积(EDE-block):
-
在 network_blocks.py 添加 EDE_block 部分的代码,包括 DFMConv 模块和 3x3 BaseConv。
-
在 CSPLayer 中修改代码,添加 EDE_Block 并删除原有的循环串联结构。
- DarkNet 中添加 CA 模块:

-
实现 CA 模块,替代 SPP 结构。
-
将实现的 CA 模块添加到 Dark5 中。
- 检测头改进:
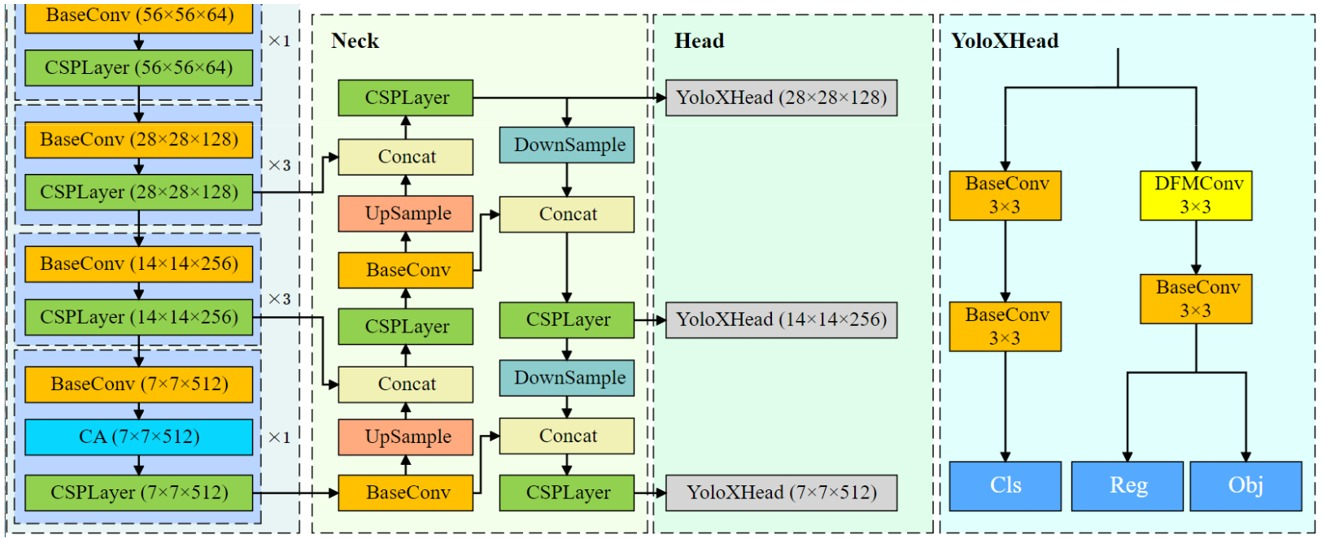
- 在 YOLOX 的检测头中,将一个 BaseConv 替换为 DFMConv。
EIoU损失函数
-
引入 EIoU 损失函数,替代 IoU 损失函数,加速训练过程,提高回归准确性。
-
EIoU 损失函数包括 IoU 损失、距离损失和宽高比损失。
改代码步骤
- CSPLayer 添加可变性卷积:
- 修改 YOLOX 中的 CSPLayer,加入 EDE_block。
class EDE_block(nn.Module):
def __init__(self, in_channel, out_channel):
super(EDE, self).__init__()
self.branch0 = nn.Sequential(
BaseConv(in_channel, out_channel, ksize=1, stride=1),
BaseConv(out_channel, out_channel, ksize=3, stride=1)
)#左支路分别经过1*1和3*3的两个BaseConv。
self.branch1 = nn.Sequential(
DeformConv(in_channel, out_channel),
nn.BatchNorm2d(out_channel),
nn.SiLU(inplace=True),
BaseConv(out_channel, out_channel, ksize=3, stride=1)
)#中支路首先经过(可变形卷积,BN归一化,SiLU激活)这三块看作DFMConv模块,然后经过一个3*3的BaseConv。
self.conv_cat = BaseConv(3*out_channel, out_channel, ksize=1, stride=1)#最后将左、中、和右(右支路就是原特征层)完成拼接后的结果压缩回需要的通道数即out_channel
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x_cat = torch.cat((x, x0, x1), dim=1)#在维度1即通道上进行拼接
return self.conv_cat(x_cat)
其中DeformConv代码如下:
class DeformConv(nn.Module):
def __init__(self, in_channel, out_channel, kernel_size=3, padding=1, stride=1, bias=None, modulation=False):
"""
Args:
modulation (bool, optional): If True, Modulated Defomable Convolution (Deformable ConvNets v2).
"""
super(DeformConv, self).__init__()
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.zero_padding = nn.ZeroPad2d(padding)
# conv则是实际进行的卷积操作,注意这里步长设置为卷积核大小,因为与该卷积核进行卷积操作的特征图是由输出特征图中每个点扩展为其对应卷积核那么多个点后生成的。
self.conv = nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=kernel_size, bias=bias)
# p_conv是生成offsets所使用的卷积,输出通道数为卷积核尺寸的平方的2倍,代表对应卷积核每个位置横纵坐标都有偏移量。
self.p_conv = nn.Conv2d(in_channel, 2 * kernel_size * kernel_size, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.p_conv.weight, 0)
self.p_conv.register_full_backward_hook(self._set_lr)
self.modulation = modulation # modulation是可选参数,若设置为True,那么在进行卷积操作时,对应卷积核的每个位置都会分配一个权重。
if modulation:
self.m_conv = nn.Conv2d(in_channel, kernel_size * kernel_size, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.m_conv.weight, 0)
self.m_conv.register_full_backward_hook(self._set_lr)
@staticmethod
def _set_lr(module, grad_input, grad_output):
grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))
grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))
def forward(self, x):
offset = self.p_conv(x)
if self.modulation:
m = torch.sigmoid(self.m_conv(x))
dtype = offset.data.type()
ks = self.kernel_size
N = offset.size(1) // 2
if self.padding:
x = self.zero_padding(x)
# (b, 2N, h, w)
p = self._get_p(offset, dtype)
# (b, h, w, 2N)
p = p.contiguous().permute(0, 2, 3, 1)
q_lt = p.detach().floor()
q_rb = q_lt + 1
q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2) - 1), torch.clamp(q_lt[..., N:], 0, x.size(3) - 1)],
dim=-1).long()
q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2) - 1), torch.clamp(q_rb[..., N:], 0, x.size(3) - 1)],
dim=-1).long()
q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)
q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)
# clip p
p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2) - 1), torch.clamp(p[..., N:], 0, x.size(3) - 1)], dim=-1)
# bilinear kernel (b, h, w, N)
g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))
g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))
g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))
g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))
# (b, c, h, w, N)
x_q_lt = self._get_x_q(x, q_lt, N)
x_q_rb = self._get_x_q(x, q_rb, N)
x_q_lb = self._get_x_q(x, q_lb, N)
x_q_rt = self._get_x_q(x, q_rt, N)
# (b, c, h, w, N)
x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \
g_rb.unsqueeze(dim=1) * x_q_rb + \
g_lb.unsqueeze(dim=1) * x_q_lb + \
g_rt.unsqueeze(dim=1) * x_q_rt
# modulation
if self.modulation:
m = m.contiguous().permute(0, 2, 3, 1)
m = m.unsqueeze(dim=1)
m = torch.cat([m for _ in range(x_offset.size(1))], dim=1)
x_offset *= m
x_offset = self._reshape_x_offset(x_offset, ks)
out = self.conv(x_offset)
return out
def _get_p_n(self, N, dtype):
# 由于卷积核中心点位置是其尺寸的一半,于是中心点向左(上)方向移动尺寸的一半就得到起始点,向右(下)方向移动另一半就得到终止点
p_n_x, p_n_y = torch.meshgrid(
torch.arange(-(self.kernel_size - 1) // 2, (self.kernel_size - 1) // 2 + 1),
torch.arange(-(self.kernel_size - 1) // 2, (self.kernel_size - 1) // 2 + 1),
indexing='ij'
)
# (2N, 1)
p_n = torch.cat([torch.flatten(p_n_x), torch.flatten(p_n_y)], 0)
p_n = p_n.view(1, 2 * N, 1, 1).type(dtype)
return p_n
def _get_p_0(self, h, w, N, dtype):
# p0_y、p0_x就是输出特征图每点映射到输入特征图上的纵、横坐标值。
p_0_x, p_0_y = torch.meshgrid(
torch.arange(1, h * self.stride + 1, self.stride),
torch.arange(1, w * self.stride + 1, self.stride),
indexing='ij'
)
p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)
return p_0
# 输出特征图上每点(对应卷积核中心)加上其对应卷积核每个位置的相对(横、纵)坐标后再加上自学习的(横、纵坐标)偏移量。
# p0就是将输出特征图每点对应到卷积核中心,然后映射到输入特征图中的位置;
# pn则是p0对应卷积核每个位置的相对坐标;
def _get_p(self, offset, dtype):
N, h, w = offset.size(1) // 2, offset.size(2), offset.size(3)
# (1, 2N, 1, 1)
p_n = self._get_p_n(N, dtype)
# (1, 2N, h, w)
p_0 = self._get_p_0(h, w, N, dtype)
p = p_0 + p_n + offset
return p
def _get_x_q(self, x, q, N):
# 计算双线性插值点的4邻域点对应的权重
b, h, w, _ = q.size()
padded_w = x.size(3)
c = x.size(1)
# (b, c, h*w)
x = x.contiguous().view(b, c, -1)
# (b, h, w, N)
index = q[..., :N] * padded_w + q[..., N:] # offset_x*w + offset_y
# (b, c, h*w*N)
index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)
x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)
return x_offset
@staticmethod
def _reshape_x_offset(x_offset, ks):
b, c, h, w, N = x_offset.size()
x_offset = torch.cat([x_offset[..., s:s + ks].contiguous().view(b, c, h, w * ks) for s in range(0, N, ks)],
dim=-1)
x_offset = x_offset.contiguous().view(b, c, h * ks, w * ks)
return x_offset
有了EDE即可完成CSPlayer
class CSPLayer(nn.Module):
"""C3 in yolov5, CSP Bottleneck with 3 convolutions"""
def __init__(
self,
in_channels,
out_channels,
n=1,
shortcut=True,
expansion=0.5,
depthwise=False,
act="silu",
):
"""
Args:
in_channels (int): input channels.
out_channels (int): output channels.
n (int): number of Bottlenecks. Default value: 1.
"""
# ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
hidden_channels = int(out_channels * expansion) # hidden channels
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
self.conv2 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
self.edeblock = EDE_block(hidden_channels, hidden_channels)#与源代码唯一的区别,在右支路加了一个EDE-block。
self.conv3 = BaseConv(2 * hidden_channels, out_channels, 1, stride=1, act=act)
def forward(self, x):
x_1 = self.conv1(x)
x_1 = self.edeblock(x_1)
x_2 = self.conv2(x)
x = torch.cat((x_1, x_2), dim=1)#在维度1即通道上进行拼接
return self.conv3(x)#拼接后再压缩回原通道
- DarkNet 中添加 CA 模块:
- 实现 CA 模块,替代 YOLOX 的 SPP 结构。
#CA注意模块
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CA(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CA, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out- 将 CA 模块添加到 Dark5 中。
# dark5
self.dark5 = nn.Sequential(
Conv(base_channels * 8, base_channels * 16, 3, 2, act=act),
# SPPBottleneck(base_channels * 16, base_channels * 16, activation=act),
CA(base_channels * 16, base_channels * 16),
CSPLayer(
base_channels * 16,
base_channels * 16,
n=base_depth,
shortcut=False,
depthwise=depthwise,
act=act,
),
)- 检测头改进:
- 在 YOLOX 的检测头中,将 BaseConv 替换为 DFMConv。
self.reg_convs.append(
nn.Sequential(
*[
DeformConv( int(256 * width),
int(256 * width)),
nn.BatchNorm2d(int(256 * width)),
nn.SiLU(inplace=True),
# Conv(
# in_channels=int(256 * width),
# out_channels=int(256 * width),
# ksize=3,
# stride=1,
# act=act,
# ),
Conv(
in_channels=int(256 * width),
out_channels=int(256 * width),
ksize=3,
stride=1,
act=act,
),
]
)
)
结论
通过以上改进,DCAMNet 在带钢表面缺陷检测中引入了可变性卷积、注意力机制和 EIoU 损失函数,提高了对不规则缺陷的检测性能和泛化能力。这些改进使得 DCAMNet 在复杂场景中更具优势,对不同形状、大小和纹理的缺陷有更好的适应性。
参考文章概述
以下是关于 DCAMNet 网络的学习笔记与复现指南的参考文章,供学者深入了解该算法及实现过程。
-
- 该文章深入解析了 DCAMNet 网络的结构和关键创新,为理解 DCAMNet 提供了详实的学习笔记。
-
- DCAMNet 论文的原始链接,提供了算法设计和实验结果等详尽信息。
-
- 该文章详细介绍了如何复现 DCAMNet 算法,为读者提供了实际操作的指导,包括环境配置和代码实现。
-
- 对 YOLOX 算法进行讲解,为理解 DCAMNet 基于 YOLOX 的改进提供了背景知识。
-
- 介绍 YOLOX 网络结构,为理解 DCAMNet 基于 YOLOX 的修改提供了基础。
-
- 对 YOLOX 代码进行解析,为读者提供了深入了解 YOLOX 实现细节的资料。
-
- 提供了一个配置好的 VOC_YOLOX 代码库,其中包含中文注释,为读者提供了可直接运行的代码实例。
注意事项
- 以上内容仅供学术研究和学习交流使用,如有侵权,请联系我进行删除处理。
- 若有任何问题或需要进一步讨论,请随时联系我的邮箱:01@liushen.fun。