使用BiLSTM神经网络+PyTorch实现汉语分词模型的训练
使用BiLSTM神经网络+PyTorch实现汉语分词模型的训练
本次实验源码及数据集已上传到Github,有需要自行下载。
第一部分:实验分析与设计
一、实验内容描述
此次实验主要是为了深入比较和评估不同中文分词方法的性能,以便于更全面地理解它们的优点和局限性。在此次实验中我将使用两种主要方法来实现中文分词:一种是基于词典的正向匹配算法,另一种是基于神经网络的双层双向长短时记忆网络(LSTM)模型。
方法一:基于词典的正向匹配算法
这种方法比较简单,在这种方法中,我们将利用一个包含大部分常用中文词汇的词典。然后,使用正向匹配算法,将待分词的文本与词典中的词汇逐一匹配。匹配成功的部分将被输出作为分词结果。这种方法的优势在于其简单性和速度,但它可能无法处理未知词汇或歧义情况。相较于神经网络非常容易实现,也不需要麻烦的数据预处理,还不需要修改数据格式,主要算法就是字符串匹配。
方法二:基于神经网络的双层双向LSTM模型
在这个方法中,我们将使用pyTorch构建一个神经网络来实现中文词语分词算法。首先,我们将准备一个中规模的中文语料文件,作为训练数据集。我们将使用PyTorch框架构建一个双层双向LSTM模型,该模型能够学习如何分词。在训练过程中,模型将学习词汇和上下文之间的关系,以便更准确地分词。
数据集
为了评估两种方法的性能,我们将使用以下数据集:
语料文件:一个包含大量中文文本的语料文件,用于神经网络的训练。该语料文件将包括各种文本类型和难度级别的文本。其中使用空格分开每一个词语,如下其中一句所示:
1 | 1. 迈向 充满 希望 的 新 世纪 —— 一九九八年 新年 讲话 ( 附 图片 1 张 ) |
测试数据:一个用于评估两种分词方法的测试数据集,包括中文文本。这些测试数据将用于比较方法的性能。其中数据为一句句话,但是没有使用空格进行分割。
测试数据结果:测试数据对应的结果,每一行都和 测试数据相对应,不过每个词语之间有空格间隔。测试数据和测试数据结果如下:
1 | 1. 测试数据:共同创造美好的新世纪——二○○一年新年贺词 |
数据预处理:准备词典、对语料文件进行分词和标记化,以及创建神经网络模型的输入数据。
模型训练:使用语料文件进行神经网络模型的训练。模型将学习如何分词。
模型评估:使用测试数据集来评估两种分词方法的性能,包括准确率、召回率、F1分数等指标。
结果分析:比较基于词典的正向匹配算法和基于神经网络的方法的性能,讨论它们的优势和不足之处。
实验验证:重复实验,以确保结果的稳定性和一致性。
通过这个实验,我们希望得出关于不同中文分词方法的性能比较,并为选择最适合特定任务的分词方法提供有力依据。
二、实验内容与设计思想
在第一种方法中,首先,我们使用简单的正向匹配算法,对于字符串中的每个字符串进行匹配。从文本的开头开始,每次匹配最长的词语,直到文本被分完为止。如果当前位置没有匹配到任何词语,则将当前位置的字符作为一个单独的词语。
具体来说,该算法的实现过程如下:
初始化一个空的词语列表tokens,以及文本的长度text_len和词典中最长词语的长度max_word_len。
从文本的开头开始,依次匹配最长的词语。具体地,从max_word_len开始,依次尝试匹配长度为max_word_len、max_word_len-1、…、1的词语,直到匹配到一个词语为止。
如果匹配到了一个词语,则将该词语添加到tokens列表中,并将当前位置i移动到词语的末尾。
如果没有匹配到任何词语,则将当前位置的字符作为一个单独的词语,并将当前位置i移动到下一个位置。
重复步骤2到步骤4,直到文本被分完为止。
该算法的时间复杂度为O(n^2),其中n为文本的长度。在实际应用中,该算法的效率较低,但是实现简单,可以作为其他分词算法的基础。
第二种方法主要需要使用pytorch,所以比较麻烦,首先我们需要对于所有句子进行预处理,由于模型无法直接输入文字,所以我们得将其进行编码,编码这里我选择的是每个字出现的频率,按照从小到大排序进行编码,这样一方面可以实现我们的编码功能,另一方面还有一部分字频特征,比较直接。通过这种方式将其转换为数字列表后,再将结果进行处理,通过上网查阅资料可知,在这种模型我们的结果需要使用编码进行标识是否是一个词语或者单独的字。编码规则如下:
1 | 1. target_dict = {'B': 0, # begin |
编码成功后,我们的每个句子转换为了数字类型,除此之外,如果有需要我们还需要将其转换为one-Hot编码,不过在torch模型中不是很需要,所以这里我们就不转换了。
数据预处理后,我们就需要创建模型了,为了模型更加贴合我们的实验,我选择了双层双向LSTM。双向LSTM(Bidirectional LSTM)是一种常用的循环神经网络模型,它可以同时考虑输入序列的前向和后向信息,从而更好地捕捉序列中的上下文信息。在分词模型中,双向LSTM可以很好地处理中文分词中的歧义问题,提高分词的准确性。
具体来说,双向LSTM可以将输入序列分别从前向后和从后向前进行处理,得到两个输出序列。这两个输出序列可以分别表示输入序列中当前位置之前和之后的上下文信息。然后,这两个输出序列可以被合并起来,得到一个综合的上下文表示,用于进行下一步的分类或预测。
在分词模型中,双向LSTM可以很好地处理中文分词中的歧义问题。例如,在中文分词中,一个汉字可能既可以作为一个词语的开始,也可以作为另一个词语的中间部分。这种歧义问题可以通过双向LSTM来解决,因为双向LSTM可以同时考虑当前位置之前和之后的上下文信息,从而更好地判断当前位置的标记。
然后,我选择了交叉熵作为损失函数,并且定义了优化器,然后将数据上传到GPU上进行运算,现在整个项目就比较清晰了。
三、实验使用环境
系统:Windows 11专业版 22H2 22621.2361
软件:Visual Studio Code
环境:Anaconda3(base):Python 3.9.13
PyTorch 2.0.1+cu118
硬件:LEGION R9000P 2021H
CPU:R7-5800H
GPU:RTX 3060 Laptop
第二部分:实验调试与结果分析
一、调试过程
首先我们实现第一种正向最大匹配分词实现汉字分词,我们的词典中有若干词汇,并且按照首字母顺序进行排序,如下图所示:

我们所需要实现的功能就是,遍历一串句子的每一个字,使用这个字及后面的若干字组成临时词汇,在列表中搜索对应的词汇,如果有这个词汇,分词,并进行下一句话的分词,如果没有,单独成词,并继续遍历下一个词汇。实现代码如下:
1 | # 定义正向最大匹配分词函数 |
其中的directory_data就是我们的字典文件,经过split函数,将其每个空格隔开的每个单词分别放入到列表中便于查询。 我们测试一条句子,得到以下结果:
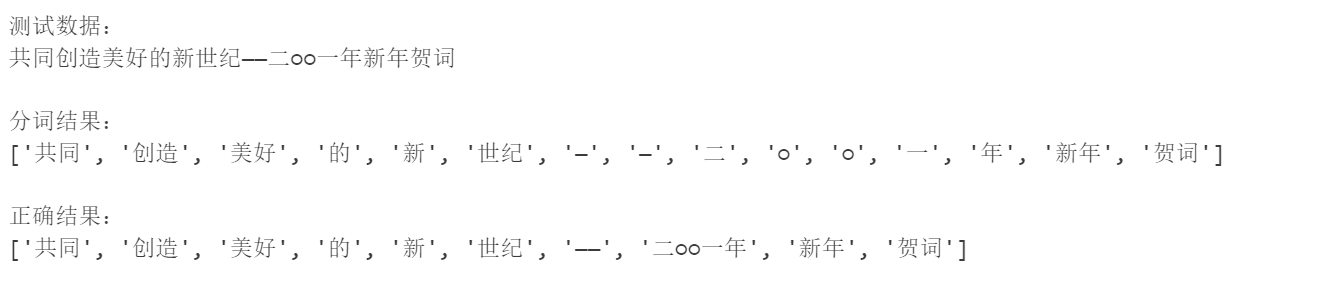
我们可以看见,这个准确率还不错,除了“—”和“二○○一年”没有出现在字典中,其他的分的效果挺好的。然后计算一下准确率,F1值,召回率参数,这一步是个比较难的点,由于是文字的原因,我们无法很好的对比他是否分割完毕或者在这里分割。为了统一标准,我们选择了,对比词汇是否正确划分出来,并且使用正确划分的词汇数量进行评判。我们写了如下代码循环进行测试:
1 |
|
最终我们得到相关数据:
正确分词数量:4983
总分词数量:5655
正确结果的词语总数:5414
准确率:88.12%
召回率:92.04%
F1值:90.04%
第二种方法我们选择使用PyTorch实现神经网络进行分词,我们首先定义一下思路我们想要实现功能,那么必须要向神经网络中传输数据,我们的数据应该是什么形状的呢?由于是句子,首先句子的长度可能会有较大变化,其次是维度,我们每个句子一行行堆砌为列表,最终的结果应该也会很大。数量多没问题,但是如果数据变长度,我们能很好地是西安功能吗?首先我写了一个BP神经网络简单实现,发现最终效果很差,所以,为了模型更好的拟合,我选择最大长度为32,大于32的句子删掉,小于32的句子末尾补零,当然我们按照所有的标点符号进行划分,确保大部分数据都能派上用场。理论可行,实践开始:
获取训练数据:我们的语料文件是每个词语之间用空格分隔开,但是我们输入数据中不应该有这些空格,这些空格应该是以标签的形式输入,所以我们首先需要将空格去掉,然后按照标点符号进行断句,经过统计,无标点符号的句子长度几乎所有都不会超过32,这样就不会浪费数据了。处理代码如下:
1 | def build_train_data(file_path): #file_path = 'data/train.txt' |
其中处理句子长度并在末尾添加零的代码写到后面,因为后面还会使用到这个数据。
下面就是我们的标签数据了,我们需要想办法将其中不同的分词保存成一种数据,经过上网查询,我选择了使用对应字母来表示每个字的位置,通过转换,我们获取到其中几条数据的输出:

模型无法识别汉字,所以我们需要给汉字编码,这里我选择使用字频字典进行编码。统计字频后保存字频文件以便于后面测试时调用,另外我们需要空缺出0的编码,以进行后续32个字符的补齐。
1 | def build_vocab_dict(file_path): #'data/train_data.pkl' |
下面我们只需要给训练数据,也就是那一串串字符搞成数字,再在末尾补0,即可达到要求。
下面我们开始定义模型类和相关参数,考虑到是一个分词模型,我们选择双向LSTM实现,为了效果达到最好,我尝试选择一个双层双向LSTM进行训练。模型定义如下:
1 | class BiLSTM_Model(nn.Module): |
这个模型中,我们可以看到,我们添加了两个双向LSTM,并在其中穿插Dropout层防止过拟合,并且在最终添加了一个fc全连接层,将最终结果转化为分类结果。然后我们只需要定义模型并训练,即可得到我们的结果。
注意训练时我们需要选择GPU进行计算,先定义模型和模型所使用的损失函数优化器,然后将模型和数据送到GPU即可:
1 | model = BiLSTM_Model(voc_size + 1, config.embed_dim, config.hidden_dim) |
通过这部分运行代码的结果我们可以看见我们的模型大致内容。

然后将数据上传到GPU上,注意在上传时我们应该选择自己的设备,如果设备不支持GPU,就可以直接进行下一步了,如果支持进行这一步骤并选择设备id以提高速度。
1 | # 将数据和模型上传到GPU进行计算 |
下面我们就可以进行训练过程了。训练过程我们每个epoch分开进行训练,训练结束后输出损失再进行下一步
1 | # 开始训练 |
这里我们可以看见很多的系数,如config.Learning_rate,config.epoch等等,这里我们是定义了一个参数类以保存各种参数,如下:
1 | class Config(object): |
最终输出结果如下:
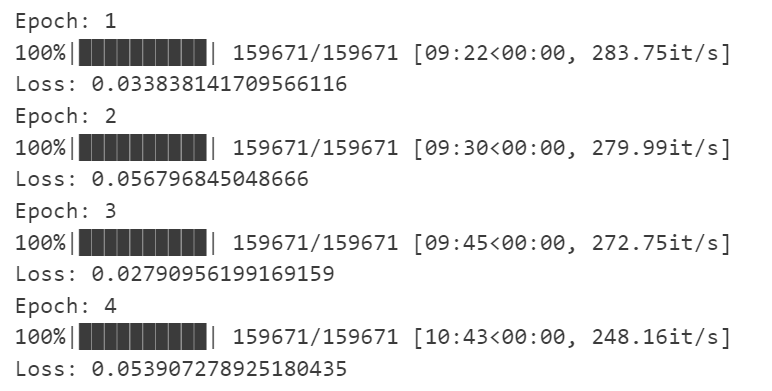
现在开始系统的测定我们的准确率,这里的召回率,我选择使用字母的对应进行测试,比如这个字符在原标签中是一个E,如果变成了其他字符,则表示错误,反之正确。当然我们的测试数据需要通过原来保存的字典转换成数据。
下面进行测试:
1 | # 将测试数据和测试结果转换为tensor |
经过测试数据的转换,处理,最终得到结果:准确率:88.04%
本次实验完毕
二、实验结果及分析
1、结果描述
在本次实验中,我们比较了基于词典的正向匹配分词方法和基于神经网络的双层双向LSTM分词方法的性能。以下是实验结果的描述:
基于词典的正向匹配方法:
该方法在测试数据上表现出较高的准确率,88.12%。大多数常见词汇能够被正确分词。
但在处理未知词汇和复杂的歧义情况时,其性能下降明显,甚至直接无法进行划分。
基于神经网络的双层双向LSTM方法:
该方法在测试数据上表现出更好的适应性,能够更好地处理未知词汇和歧义情况。
虽然在测试数据中两者准确率类似,但是在不在词典或语料中的词汇中,准确率相对较高,尤其在复杂文本类型中,其性能明显优于基于词典的方法。
2、实验现象分析
在分析实验结果时,我们观察到以下现象:
基于词典的正向匹配方法在处理常见词汇上表现良好,但在面对未知词汇和歧义情况时遇到挑战。
基于神经网络的双层双向LSTM方法能够更好地理解上下文信息,从而更好地处理未知词汇和复杂语境。
3、影响因素讨论
实验结果受以下因素的影响:
训练数据:基于神经网络的方法受训练数据的质量和多样性影响。更大规模、多样性的语料库有助于提高模型的性能。
模型架构:选择双层双向LSTM模型是为了考虑上下文信息,但其他架构可能在不同任务上表现更好。
测试数据:测试数据的多样性和难度对两种方法的性能评估至关重要。
4、综合分析和结论
综合分析实验结果,我们得出以下结论:
基于神经网络的双层双向LSTM分词方法在处理中文分词任务时具有更高的适应性,特别是在面对未知词汇和复杂上下文的情况下。
基于词典的正向匹配方法适合处理简单的文本和常见词汇,但在处理复杂文本时表现不佳。
因此,选择合适的分词方法应该取决于应用场景和任务要求。如果需要更好的泛化性能和适应性,基于神经网络的方法可能是更好的选择。然而,基于词典的方法仍然具有在一些特定情况下表现良好的优点。
三、实现小结、建议及体会
在此次实验中,我使用了两种不同的中文分词方法,一种基于词典的正向匹配,另一种基于神经网络的双层双向LSTM模型。这体现了自然语言处理领域的多样性,不同方法适用于不同的应用场景。
在实验中,我们测试了两种方法在各种方面的差异,基于神经网络的方法在面对未知词汇和复杂上下文时表现更好,但是训练时间较长。而基于词典的方法适用于处理常见词汇和简单文本,并且不需要进行训练即可直接运行。这突出了每种方法的优势和局限性。
为了保证实验的准确性,我重复进行了几次实验,最终得到了相对稳定的结果,并且进行对比,体现了实验的严谨性。
实验还启发了我思考如何进一步改进中文分词方法。可以尝试不同的神经网络架构、更大规模的数据集、迁移学习等方法来提高分词性能。
这个实验不仅让我更深入地了解了中文分词方法的工作原理,还强调了数据的重要性以及不同方法在不同情境下的适用性。这将有助于我更明智地选择和应用中文分词方法,以满足特定任务的需求。
实验中所有源码均以上传Github,链接在最上方,需要者自行下载。
 微信
微信- 支付宝



博客架构概览:
⚙️框架核心:Hexo
🕹️界面设计:Butterfly
🔮安全保障:1Panel
🎰服务器:初七云
🎲CDN加速:多吉云,腾讯云