


浅谈AIGC论文检测
碎碎念
本文没有任何攻击倾向,只是想简单聊聊个人对当前AIGC检测的看法。
六月初,怀着忐忑的心情,将自己辛辛苦苦写出来的论文(依托答辩)交上去后,经过了两天两夜的降重和AIGC检测降重的折磨,通过网上所谓的AI降低AIGC查重率,人工降AIGC查重率的方式,为了省钱,我自己一点点搞,最终终于降下来了,但是相应的,我的论文也被改成了降智版。
虽然说降智了,但是好在最终也是顺利毕业滚蛋了,毕业十余天,来谈谈我对于AIGC检测的看法。
AIGC检测
检测原理
既然要聊AIGC检测,那咱就先说说它到底是怎么判断你是不是AI写出来的。
目前最常见的方式是看“困惑度(Perplexity)”——你可以简单理解为“AI觉得这段话好不好猜”。AI自己写的东西,对它自己当然毫无压力,预测很准,困惑度就低;而人写的,尤其是稍微跳跃点、语义转折多的句子,它就有点懵,困惑度就高了,于是它觉得:“这可能是人类写的”。

比如以上这俩卧龙凤雏,意大利面拌42号混凝土这玩意,AI确实是想不出来的。
除了这个核心指标,不少检测工具也会综合一些句式复杂度、用词多样性、逻辑一致性来打分。比如你老是用短句、重复词、语气随意,它觉得“挺人味”;反之如果你语句通顺、结构完整、逻辑清晰,它就皱眉:“太规范了,有点像机器,正常大学生怎么能写出这么工整的文章(悲)”。

你越认真、越努力润色,它反而越不信你是人写的。
目前很多检测工具像是GPTZero、ZeroGPT、OpenAI的Classifier(虽然后来下线了),以及国内一些AI写作监测系统,基本都是这套思路延伸出来的,判断逻辑性,判断困惑度,判断用词。
检测现状
说实话,现在主流的AIGC检测工具准确率并不乐观。尤其是你写论文的时候,一旦用了点专业术语、套了两层逻辑,检测结果立马就飙红,AIGC率70%、60%(大部分本科要求为30%),吓得我以为自己不是人了。

更讽刺的是——你如果想“刻意通过检测”,反而要把文字写得土一点、乱一点、有点像喝醉后的碎碎念,这样“困惑度”一下子就上来了,检测工具反而说:“嗯,这像人写的。”但是这也严重违背了论文的科学性和严谨性。
这种检测逻辑本质上就较为机械,虽然我不知道他的具体逻辑,但是我是清楚他的检测结果的(嗯对没错,花钱买了三四次检测)。它看的是“表面语言特征”,而不是你创作的过程,更别提上下文、思路展开之类的东西了。所以很多时候,它判断的根本不是“你是不是AI”,而是“你像不像它见过的AI文本”。
降低AI率
AI降AI
这听起来很荒诞,但实际上一点也不合理。为了通过AIGC检测,很多人开始反过来“用AI修改AI”,用AI来修改人写的内容,目的就是让检测工具“误”以为这是“人写的”。有些降重工具会自动加入口语化表达、打乱语序、替换同义词,或者刻意插入语气词和错别字——简单说,就是把一段正常话“降智处理”一遍。
结果就是,你原本认真写的一篇论文,本身逻辑性可能本来较强,但是由于需要降低AIGC检测率,被迫改得四不像,好好的逻辑也被削弱。很多时候“AI帮你把你写的话写得更像人写的一样”,只是为了骗过另一个AI,发展到这里,性质已经变了,这已经不叫降重了,更像是在哄骗小孩,AI是流水线,人工是“造假师”,把机器味搞成“农家手工味”。
坦白说,我自己也试过这种“AI降AI率”的方法。刚开始确实觉得挺快,效果也“显著”——只要不在乎内容质量的话。但用完后我很快就放弃了,因为那些降重工具实在太糙,能把我辛辛苦苦写的段落搞成一坨shit,句子变得生硬、逻辑混乱,完全不像我写的。最后我还是选择一点一点地手动修改,虽然慢,但至少保住了原本的思路和表达。
以上是我在Linux.do论坛上找到的一个佬友的帖子,测试了一下,效果出奇的好,prompt如下:
1 | 你的角色与目标: |
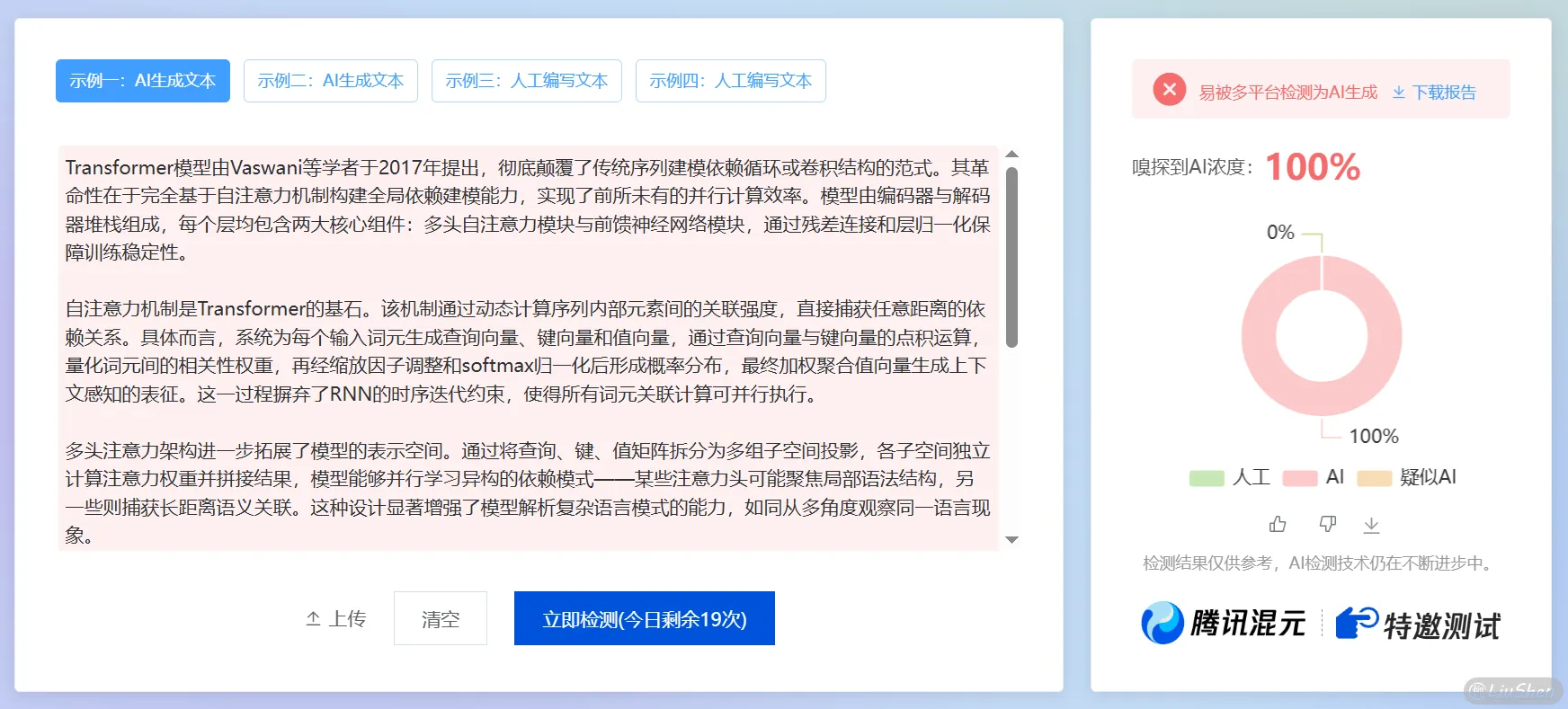
为了测试这个Prompt的实战效果,在这里我做了一个简单的测试,首先我尝试用AI生成了一段文本:请给我写一段介绍transformer的论文片段,DeepSeek返回回来的结果如下:
1 | Transformer模型由Vaswani等学者于2017年提出,彻底颠覆了传统序列建模依赖循环或卷积结构的范式。其革命性在于完全基于自注意力机制构建全局依赖建模能力,实现了前所未有的并行计算效率。模型由编码器与解码器堆栈组成,每个层均包含两大核心组件:多头自注意力模块与前馈神经网络模块,通过残差连接和层归一化保障训练稳定性。 |
再通过大家常用的朱雀AI检测助手进行检测,不出意外,检测结果为 AI浓度100% :
下面我将该AI文段,通过这段降重Prompt尝试降重,这里我用的是Gemini 2.5 Pro模型,众所周知Gemini是文科生,非常适合这种文本内容。
经过降重后的文本结果如下:
1 | Transformer模型是由Vaswani等学者在2017年所提出的,它彻底颠覆了传统序列建模工作依赖于循环或是卷积结构的既定范式。它的革命性主要体现在,完全是基于自注意力机制来构建出全局依赖的建模能力,从而得以实现前所未有的并行计算效率。整个模型是由编码器以及解码器的堆栈所组成的,其中每一个层都包含了两大核心组件,也就是多头自注意力模块以及前馈神经网络模块,并且借助残差连接和层归一化来保障训练过程的稳定性。 |
再对降重后的文本进行检测,毫无意外,检测结果几乎为0。

简单对比后不难发现,所谓的“降重”,其实就是不断加入主语、语气词、过渡词,或者把原本正常的句式扭来扭去,以此来“提高困惑度”。这种方法在AIGC检测中确实效果显著,能让AI判定为“更像人写的”。但问题是,如果放在论文、期刊这类对语言规范性和专业性要求极高的文体中,这种方式是否真的合适?这个问题恐怕还需要进一步讨论。
付费降AI
相比自己折腾,有些人会选择在网上购买现成的“降AI”服务。宣传口号一个比一个响亮——什么“100%人工降重”、“包过AI检测”、“专业语义重构”、“论文不过全额退款”,听得跟保过驾校似的,让人不由自主地点进去看几眼。至于它到底是不是人工改?有没有真“语义理解”?我们不清楚,客服也不会说,只有商家的钱包最清楚。
更离谱的是,现在不少平台干脆搞起了“自家打假自家解药”的生意。一边提供“权威AI检测”,报告上满屏红黄条,把你写得像AI的嫌疑放大到极致;另一边又推出付费降重服务,承诺“快速通过检测”、“修改后立即生成新报告”。检测你、吓唬你、再收你钱,这一整套流程下来,堪称闭环收割,精准打击焦虑用户群体。
这种做法已经不仅仅是割韭菜了,更像是——自己放火,自己卖灭火器,顺带把你钱包也烧个精光。说好听点是“提供完整服务链”,说难听点就是又当裁判又当运动员,比赛还没开始结果就写好了。
最可怕的是,这类操作在不少高校外包系统、论文投稿机构中都在真实上演,很多学生和写作者明知道其中猫腻,也只能被动配合。毕竟,和一份被误判为“AI生成”的报告比起来,掏点钱换个安心,听起来似乎划算得多。
这个点不敢细讲,我怕有些商家顺着网线过来擂我
AI的普及
AI使用率
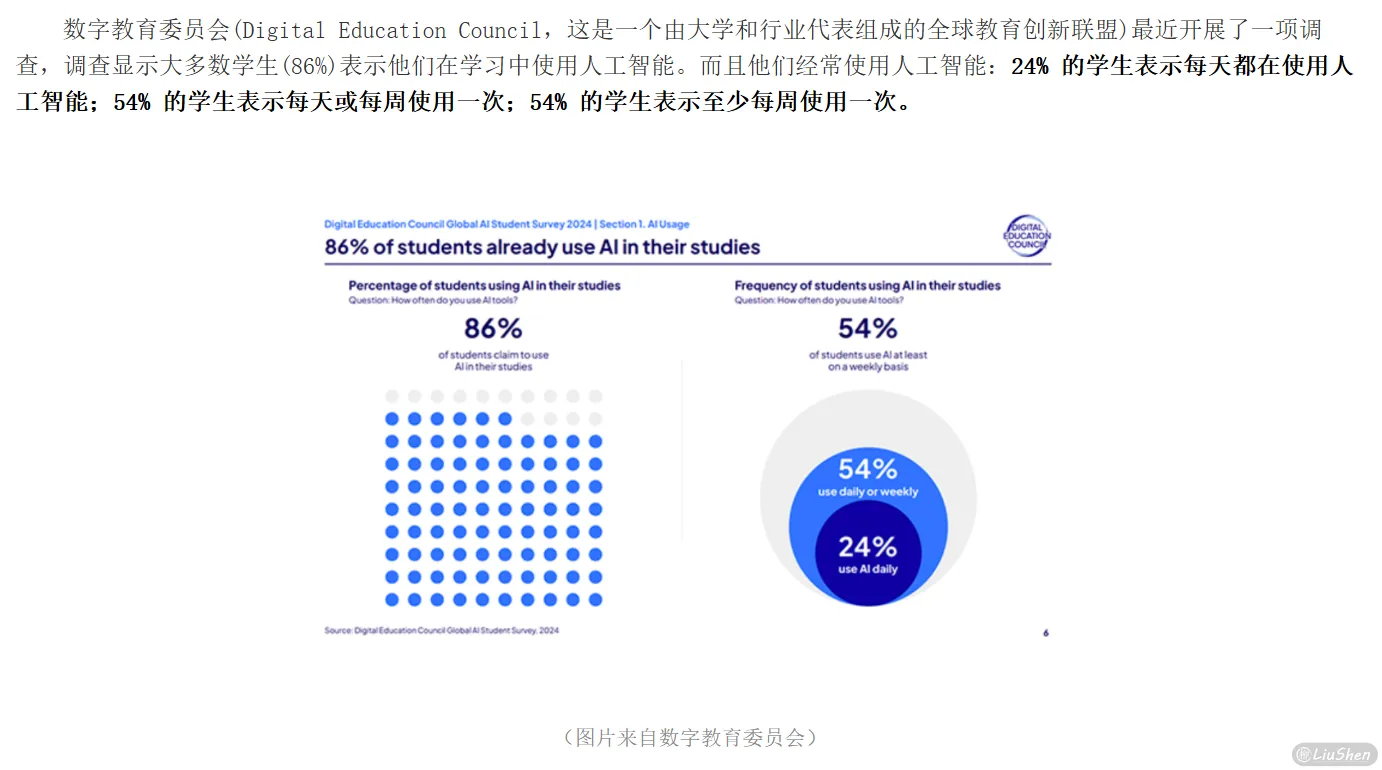
近几年,AI工具的使用率一路飙升,已从实验室走入写作、学习、创作的每个场景。根据近期报道,越来越多高校和机构开始正式接纳AI辅助写作,大学生群体中使用率已超过50%。无论是撰写论文提纲、翻译摘要,还是潤色语句、优化结构,AI几乎成为继“搜索引擎”之后的第二大写作帮手。可以说,今天这个年代,想完全不用AI来辅助写作,反倒显得有点“落后”。
AI工具化
AI被妖魔化的一个原因在于它的“自动生成内容”,让人以为使用AI就是偷懒、作弊(虽然就是)。但实际上,AI更像是一个主动型搜索+内容辅助系统。它输出的东西,需要我们去筛选、判断、修改,过程并不比“自己写”简单多少。就像你用百度或谷歌查资料,没人会说你“抄袭”;你用有道词典翻译句子,也不会被当成作弊——AI其实只是多了一点“提炼能力”。
人类的进步,总是朝着更加省力的方向走的。从石器到铁器,从算盘到计算机,一次次的技术革新都是为了让人类少动点手、多动点脑。AI也是一样。虽然说自动生成内容确实有点偷懒的嫌疑,但能够偷懒,本身就是技术进步的标志之一。问题不在于你是不是用了省力工具,而在于你有没有在使用之后,把这个东西真正消化吸收。
所以我一直认为,偷懒不是问题,理解才是关键。哪怕你是拿AI帮你写的,只要你能讲得清楚、答得上来、融入自己的思路,那这段内容就属于你自己。毕竟,知识不是靠谁手敲的键盘来衡量,而是看你脑子里有没有东西。
真正的问题不是“用了AI”,而是“你有没有学会它说了什么”。而这,也是我个人认为,教育和写作评价真正应该关注的地方。
风口
AI已经不是未来了,而是现在进行时。从大模型爆发、写作工具流行,到各行各业纷纷接入AI辅助系统,陈旧的思维已经不适合这个时代,我们可以很明显地感受到,这场浪潮已经席卷过来。谁掌握工具,谁就掌握了效率;谁适应得快,谁就能先一步起飞。
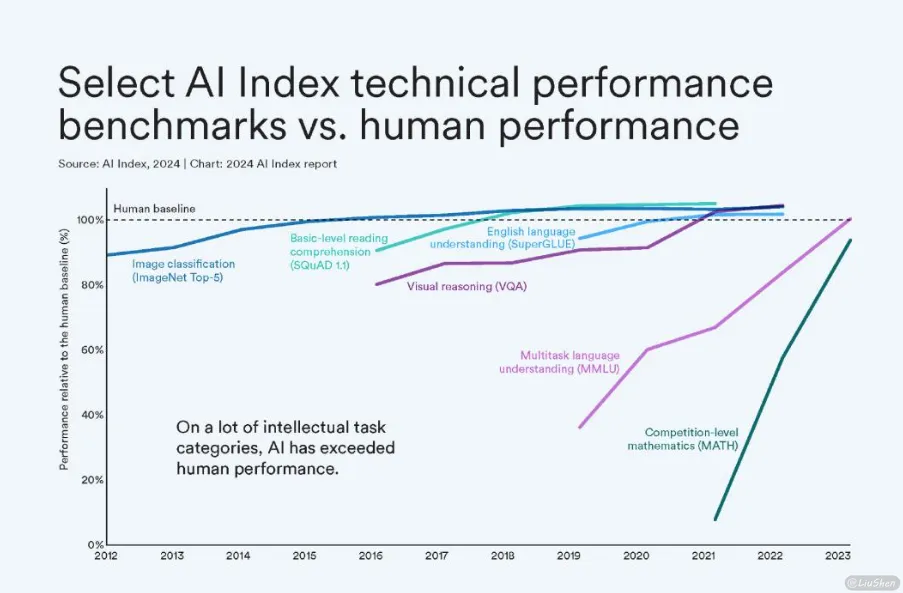
在教育、创作、办公这些原本“人力密集”的领域,AI正以一种前所未有的速度改变着我们的工作方式。对学生来说,这是写论文、写作业的“外挂”;对内容创作者来说,这是构思、起草的“发动机”;甚至对程序员、设计师来说,它也正在成为日常工作的一部分,AI从始至终。都不是替代性的发展。
但和所有风口一样,一旦火了,就会有人割韭菜,也会有人被反割。这其中最典型的,就是所谓的 AIGC 检测和降重产业链。一边说“要防范AI滥用”,一边自己又靠AI吃饭,割的不是韭菜,是焦虑。
AI是风口没错,但别把风口当陷阱跳进去,也别因为别人的风声鹤唳,把自己吓退了。风口来了,站稳再说,方向选对,比起一味“规避”更加的重要。
个人看法
说到底,AIGC检测效果不佳,不是因为技术不到位,而是因为它本身就是一个悖论。AI本来就是基于人类海量语料训练出来的,它的目标就是“写得像人”。而当它真的越写越像人的时候,我们却又反过来用另一个AI来判断“这个像人,是不是太像AI”。这不是自我否定吗?
你发展得越好,就越难分辨,这就注定了检测这件事迟早会陷入死胡同。现在写作场景里已经逐渐出现了内容生成的LLM、内容检测的LLM、内容降重的LLM,三者互相打架、互相模仿、互相规避,逐渐形成一个闭环、一个死锁。它们彼此围绕着“像不像人类”这个标准不停内卷,结果就是谁也说服不了谁。
就像上面提到的那样,我们真正应该关注的从来不是这段话是不是AI写的,而是——你自己有没有理解?你能不能讲清楚?你是不是真的吸收了这个知识?一篇文章是你敲出来的还是你生成出来的,并不是决定你有没有学会的核心指标。你可以用AI,但你不能让AI替你思考;你可以参考它的表达,但你最终要有自己的表达。
AIGC检测可能还能继续发展下去,但它注定无法决定一个人的真实水平。工具可以帮你写,但不能帮你理解。真正属于你的内容,不在文档里,而在你脑子里。
参考文献
每日一图
图片来自哲风壁纸

 微信
微信- 支付宝




博客架构概览:
⚙️框架核心:Hexo
🕹️界面设计:Butterfly
🔮安全保障:1Panel
🎰服务器:初七云
🎲CDN加速:多吉云,腾讯云



